Implement custom retry logic with SQS & Lambda - Part I - using SQS delayed messages

Table of Contents
It is a very common pattern that you process messages in a SQS queue with a Lambda function. And when there is an error in the Lambda execution, the message will be sent back to the queue if the retries are not set up. If the retries are set up in the Lambda function, it will perform the retries and if still not successful, the message will be sent back to the queue.
And depending on the visibility timeout of the message, this process continues until the message is processed successfully or deleted from the queue.
Basically, this retry mechanism depends on the visibility timeout and happens in regular intervals.
Sometimes, we might need more control over the retries by retrying in arbitrary intervals or having exponential backoff. With default behaviour of SQS, Lambda and Event Source Mapping, this is not simply possible.
Here, I am going to discuss a solution where we can retry a failed message with a custom interval and with a condition based on how many times the message should be retried.
Architecture #
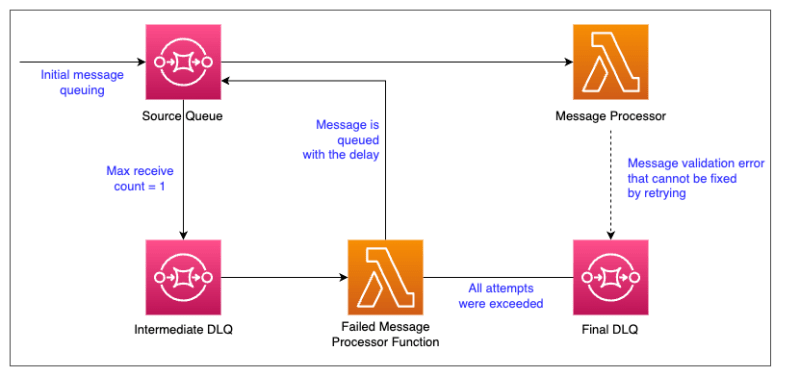
How it works #
Let’s assume you have a message with this structure. Here, data includes the payload your application needs and metadata is used to identify the message and any information that is used by infrastructure to process the message.
{
"metadata":{
"message_id":"22200000-0749-2113-8e00-000a2b111191"
},
"data":{
// message payload needs to be processed.
}
}
-
Source Queue is the entry point where this message is added to be processed by Message Processor Lambda Function.
-
In Message Processor Lambda Function, first it validates the message scheme to verify the metadata and data elements are there and the message Id is included in the meta data as an uuid.
-
If this schema validation fails, it sends the message directly into Final DLQ without retrying, because simply retrying will not fix this issue.
-
If the message is valid, let’s assume that LambdaX needs to call an external system to successfully process the message, but this external system has some issues so the message processing fails. Then it raises a Runtime exception.
-
Then the message is sent back to the source queue.
-
On the Source Queue, there is a Dead Letter Queue (namely Intermediate DLQ) configured. Also, there’s a condition set for message max receive count as 1. So, when the failed message is received, it will be sent directly into the DLQ.
-
This Intermediate DLQ has a Lambda function (Failed Message Processor Lambda Function) listening to it.
-
So, this Failed Message Processor Lambda function starts processing the message.
-
The Failed Message Processor Lambda function has several responsibilities.
-
First it increments the retry attempt count by one if it already exists or if not, set as 1 and add it into the metadata of the message.
-
Then, it checks if the number of retry attempts exceeds the pre-defined limit. Here I have used a max retry attempt as 5.
-
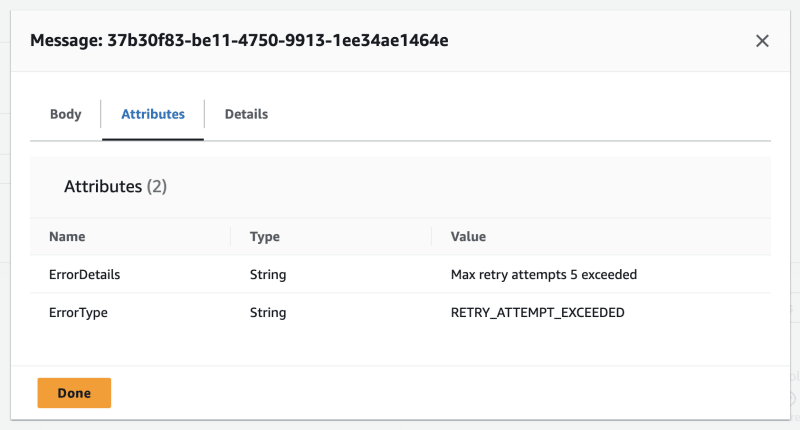
If retry attempts exceeded the max amount, then the message is moved into the final DLQ with a Error Type and Error Details as follows:
-
If not, it chooses a random number of seconds between 0 and 900 and sends a message to the Source Queue with the same payload with the delay time as this random seconds. Also, this message contains the next retry attempt time based on the delay.
-
Message that was sent to the Source Queue will look like below:
{
"metadata":{
"message_id":"22200000-0749-2113-8e00-000a2b111191",
"retry_attempt":1,
"next_retry_time":"2023-10-13T22:52:00.091307Z"
},
"data":{
"location_name":"Amsterdam",
"location_id":12345
}
}
-
Once the message is sent to the Source Queue, it will not be available to process until it reaches the delayed seconds defined.
-
Once the message is available to process, this cycle will continue until the message is processed successfully or sent to the Final DLQ.
Try this yourself #
I have a public GitHub repository created if you need to set up this project in your own AWS environment.
Clone the repository at: https://github.com/pubudusj/retry-with-sqs-delay-messages
Set up #
This is implemented with CDK and Python. So you need to have Python, AWS and CDK CLIs installed.
###Test: Once stack is deployed, send below message into the Source Queue:
{
"metadata":{
"message_id":"22200000-0749-2113-8e00-000a2b111191"
},
"data":{
"location_name":"Amsterdam",
"location_id":12345
}
}
Result #
If you check the log group of Message Processor and Failed Message Processor Lambdas, you can see the records of the message payload with different retry attempts and next retry times for each retry attempt.
Also, after 5 unsuccessful retries, you can see that message will be available in the Final DLQ with the error attributes.
Please Note: The max no of seconds can be set as the delay time in SQS is 900 seconds (15 minutes). So, this solution works only if you need to retry within the next 15 minutes.
Summary #
It is a common use case where you have to retry failed messages. However, the default retry mechanism provided by SQS & Lambda might not be sufficient for your business logic.
Main advantage of this approach discussed here is that you have more control over the retry mechanism and you can fine tune it as per your business needs. For example, here, you can control the max retry attempts and the frequency and the logic of how to determine the next retry attempt time.
👋 I regularly create content on AWS and Serverless, and if you’re interested, feel free to follow / connect with me so you don’t miss out on my latest posts!
- LinkedIn: https://www.linkedin.com/in/pubudusj
- Twitter/X: https://x.com/pubudusj