
Load Data From S3 to Postgres using Step Functions

Table of Contents
It is a common use case to load data to a database from a large set of files in formats such as CSV, JSON or parquet. This is especially useful in an ETL process where you need to load data into a database in a regular interval.
There are many factors that decide how fast and reliable your data is loading. Apart from the limitations the database engine has, capabilities of the service/tool you are using is a major factor in how efficiently the data load can be performed. For example, data can be loaded parallel, sequential or may be as batches. And having a better retry mechanism is also important when there is a failure.
In this post, I discuss how we can use AWS Step Function’s latest feature — Distributed Map — to load CSV files located in S3 bucket into a Postgres database. Using Distributed Map, it is easy to parallelise the data loading and effectively retry if there’s any failure. Also you will have better visibility in case of a failure.
How it works #
Here, we utilise the AWS S3 extension for Postgres to load data from s3 to Postgres.
We first load data into a temporary table and once the data load is completed, the existing table is backed up and then the temp table will be renamed to the main table. For that we use two additional schemas along with the default ‘public’ schema of the database.
Using Step Functions, we orchestrate these steps in one execution to load data for a single table.
Prerequisites #
-
Create a RDS Postgres database with public access**
-
Create a parameter in SSM Parameter Store to store the connection string to Postgres database Ex: in the format of postgresql://[username]:[password]@[RDSEndpoint]:[Port]/[DatabaseName]
-
Create two additional schemas in the database as follows:
CREATE SCHEMA dataimport; CREATE SCHEMA databackup; -
Install AWS S3 extension for Postgres
CREATE EXTENSION aws_s3 CASCADE -
In order to install the application, you need AWS SAM CLI installed in your local machine.
Please note: For demonstration purposes, RDS instances need to be created with public access. For a production system, you need to deploy the RDS instance more securely in private subnets and update IAC code mentioned below accordingly for Lambda functions to access RDS instance.
Set up #
-
Clone the repository https://github.com/pubudusj/s3-to-postgres-with-stepfunctions
-
Run below command to install the project:
sam build && sam deploy -g -
This will prompt you to input
DbConnectionStringSSMPathandRDSDatabaseArn. Please note: Input DbConnectionStringSSMPath without leading slash/ -
Once the stack is deployed, there will be 3 values in the output:
S3SourceBucket,RDSRoleandSNSTopic. -
Attach the RDS role into the database under
Manage IAM roleswiths3Importas the feature. -
You can subscribe to the SNS topic created, so you will be notified in case of a failure.
State Machine #
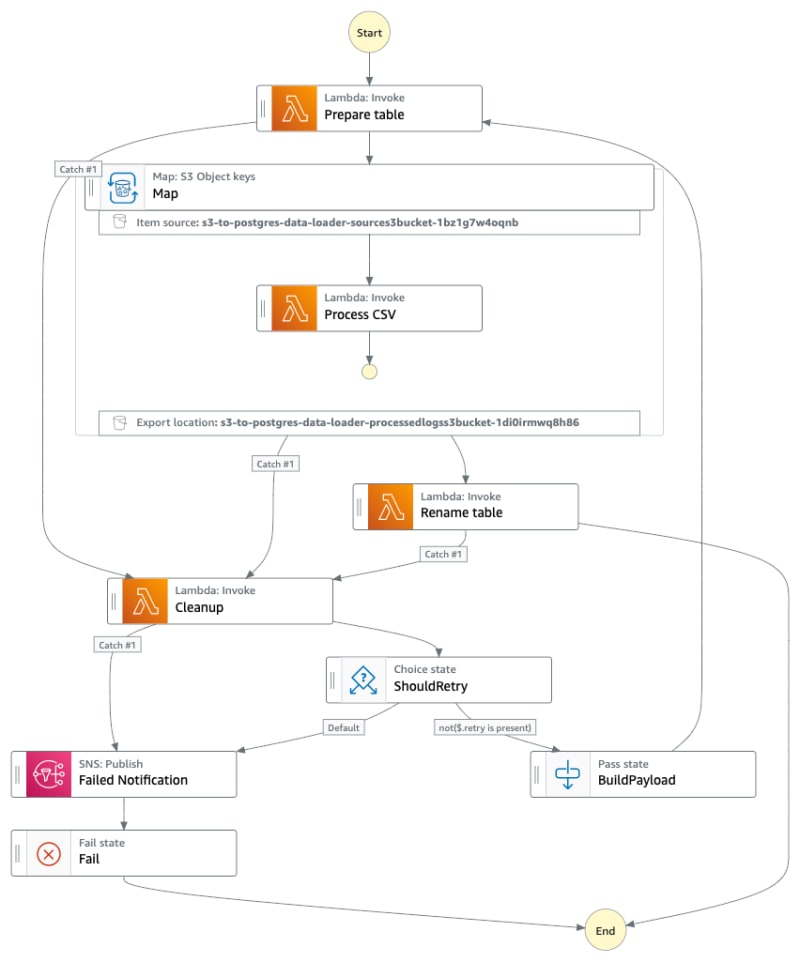
Testing with Sample Data #
To test the functionality, I have used the free data set available at https://registry.opendata.aws/noaa-gsod/. This includes a lot of data, so for the testing purposes, use only the data for 2021 and 2022.
AWS Cloud shell is best for directly syncing these data into your source s3 bucket. Open a cloud shell in your AWS console and run the command below replacing the S3SourceBucket value from the stack output.
aws s3 sync s3://noaa-gsod-pds/2021 s3://[S3SourceBucket]/year_2021
aws s3 sync s3://noaa-gsod-pds/2022 s3://[S3SourceBucket]/year_2022
This will sync data to your s3 bucket directly from the source.
If you have your own dataset, update the get_queries_for_table function at src/share_resources/db.py with the table structure relevant to your CSV data set and re-deploy the stack. Also, the table name must match the path of your data set in S3 bucket.
Ex: s3://[S3SourceBucket]/[table_name]/abc.csv
Once test data is in your source s3 bucket, initialise a Step Function execution with below input.
{
"table": "year_2021"
}
This will start sync data into your Postgres table: year_2021
Adjustments/Customisations #
-
This data load functionality depends on the performance of your database. So you might need to adjust
MaxConcurrencyandMaxItemsPerBatchparameters in your State Machine. You can adjust the ToleratedFailurePercentage value to continue to load data even if the error limit is within this value. -
Here, I use one retry if there is a failure, but by modifying the logic in the ShouldRetry step, you can increase this.
-
You can extend this functionality by adding indexes, constraints, stats, etc. to the table. For that, you can modify the Rename Table Lambda function.
Tips/Lesson Learned #
-
Always use batching and set sensible max concurrency — This will help to control the load into your database and API calls to Parameter Store.
-
Use ToleratedFailurePercentage — Depends on your requirement, this helps to load most of the data even if there is a small amount of files failed to import.
-
Use express child executions — This helps to reduce cost. If the child execution can run within 5 minutes and doesn’t use standard workflow specific functionality (ex: sync or wait for callback integration patterns). This is a great way to reduce costs.
Conclusion #
Using the Step Function Distributed Map you can load data into a database efficiently and in a much controlled manner. Using the in-built retry and error handling along with the tolerated failure settings are helpful to mitigate any errors without any intervention from the outside.
Useful Links #
-
Distributed Map documentation: https://docs.aws.amazon.com/step-functions/latest/dg/concepts-asl-use-map-state-distributed.html
-
Blog Post Step Function Distributed Map: https://aws.amazon.com/blogs/aws/step-functions-distributed-map-a-serverless-solution-for-large-scale-parallel-data-processing/
-
Standard vs Experess workflows: https://docs.aws.amazon.com/step-functions/latest/dg/concepts-standard-vs-express.html
👋 I regularly create content on AWS and Serverless, and if you’re interested, feel free to follow / connect with me so you don’t miss out on my latest posts!
- LinkedIn: https://www.linkedin.com/in/pubudusj
- Twitter/X: https://x.com/pubudusj