Design a mission critical serverless application for high resilience

Table of Contents
In the current business landscape, organisations from startups to enterprises, are increasingly relying on software systems to drive operations, decision-making, and to get advantage over their competitors. Because of that, the reliability and efficiency of their software systems are critical.
In this context, the emergence of cloud computing has been a game-changer. To take the advantage of the cloud a step further, serverless technologies have been a choice of many organisations to innovate fast with scalability and cost efficiency.
Resilience of a software system can be defined as the ability to withstand and recover from unexpected failures, faults, or adverse conditions while maintaining essential functionality and performance.
So, there are 2 main goals to achieve:
- Withstand and recover from unexpected failures.
- Maintaining essential functionality and performance.
In this blog post I discuss five simple solutions we implemented to improve the resilience of the AWS serverless application I am working on at PostNL — the EBE (EventBroker E-commerce)
About PostNL and the EBE #
PostNL is the no. 1 logistic provider in the Benelux region. On average, we deliver 6.9 million letters and 1.1 million parcels a day. This makes PostNL the preferred logistic choice in the region. To cater this demand, there are multiple software systems required to work together. Not only working together, but these systems must maintain a certain amount of performance to ensure a smooth operation. For an organisation like PostNL, it is really important to maintain high resilience as most of our systems are mission critical.
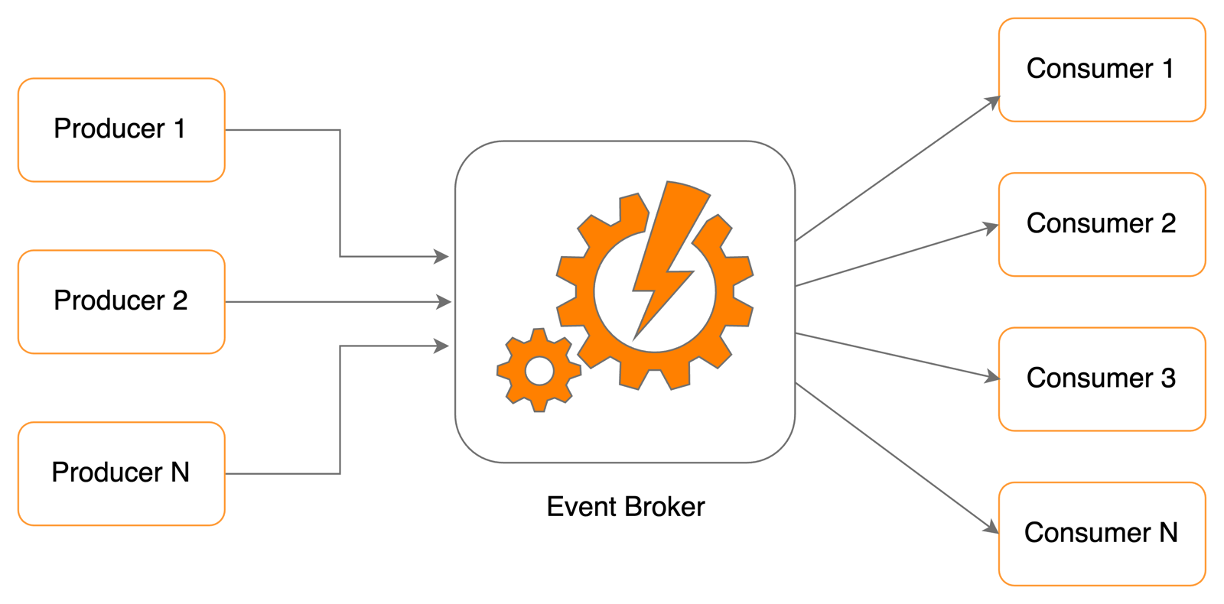
Event Broker E-commerce (EBE) is one of the mission critical applications within PostNL. It is a self service application and built using AWS serverless services.
As the name implies it is responsible for receiving messages from different producer applications and delivering them to one or more applications that are subscribed to those events. Producers send messages into EBE using SQS or HTTPS endpoints and EBE delivers the messages to the consumers via SQS or HTTPS end points. EventBridge — the serverless event bus offered by AWS — is the heart of the application that routes messages to consumers according to a given rule. For a given day, we process an average of 10 million messages within the EBE system.
Below are five design decisions taken to maintain robust resilience in the EBE system to make sure it recovers from unexpected failures while consistently delivering expected performance.
1. Minimise the blast radius #
We have hundreds of producers and consumers connected our systems. And the EBE system was architected in a way that there are very limited resources shared among individual producers and consumers. When a new producer or consumer registers in the system, we deploy a distinct set of resources (such as SQS queues, DLQs, Lambda functions, CloudWatch alarms, etc.) that are specific to the particular producer or consumer.
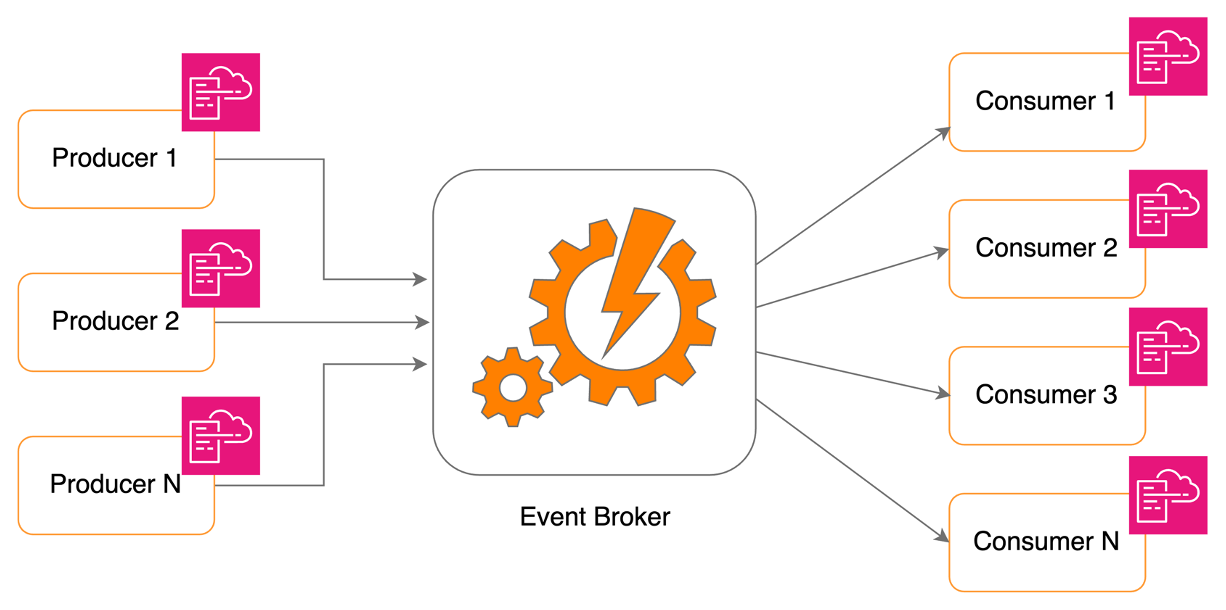
With this approach of independent CloudFormation stacks, we ensure that any failure occurring in one producer does not impact other producers. Similarly, if one consumer encounters a failure, the remaining consumers remain unaffected by it. This design enhances high resilience within the system, ensuring smooth operation even during unexpected events.
This approach comes with its own set of trade-offs, particularly concerning AWS limits, which is suitable for a in-depth analysis in a separate blog post.
2. Storage first #
When a message is received by the EBE, the responsibility of the producer is over. Then, it is EBE application’s responsibility to deliver the message to the consumer application. Also, the communication between a producer and the EBE is one way. If EBE lost a message, there is no way we can request is from the producer application. So, it is crucial for the EBE to ensure that no messages are lost under any circumstances.
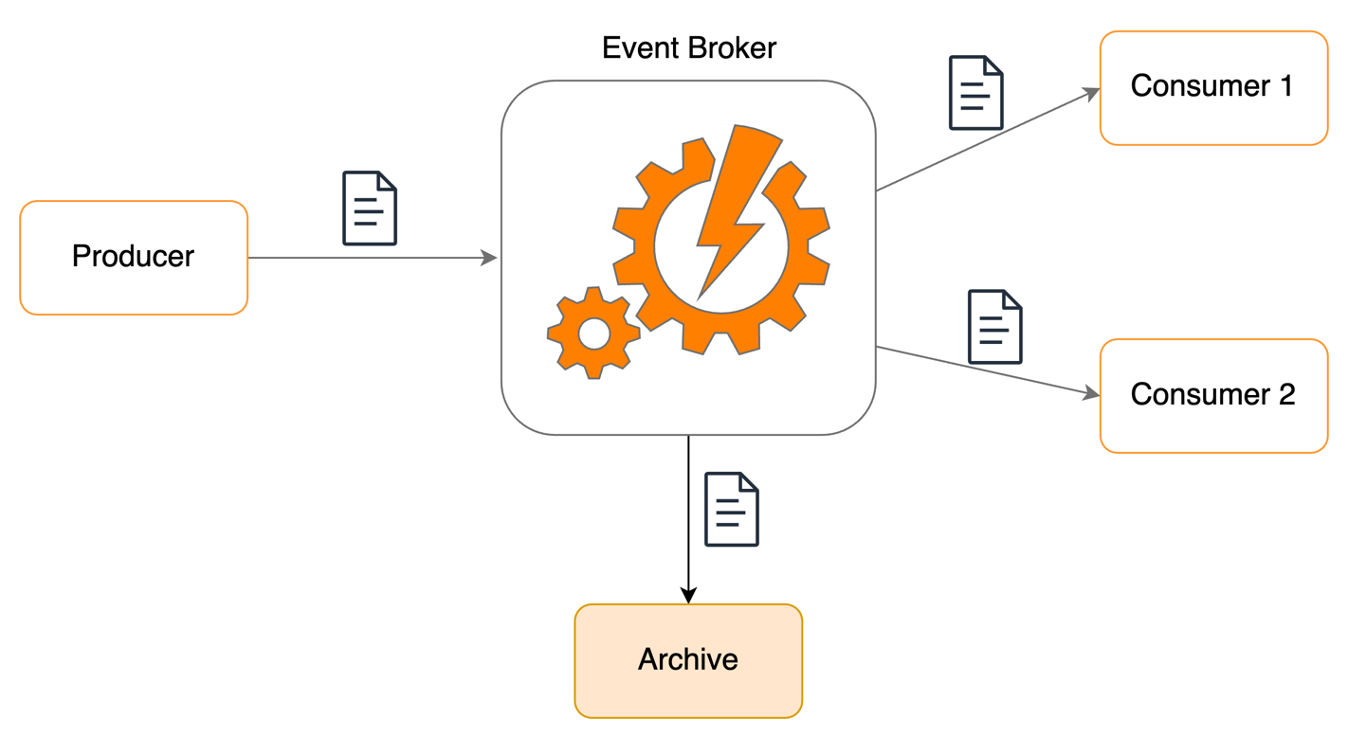
To prevent any message loss, we have implemented a storage-first approach. Every message received is stored within our system until it is successfully delivered to the consumer applications. Primarily, we utilise SQS Queues and DLQs to ensure message retention within the EBE until the deliveries are completed.
Further, the system archives all the messages using EventBridge, allowing consumers to replay events within a window of 3 days using EventBridge’s replay option.
This combination of the storage-first approach with a replay option ensures the messages are available within EBE until all the deliveries are successful, hence significantly enhancing the system’s reliability and resilience.
3. Fallback plan — Dead Letter Queues (DLQs) #
We use DLQs where ever possible. In the event of a failure occurring within the system, we use a DLQs to capture and manage it effectively. In that way we won’t lose the messages. So, DLQs are the fallback plan or the safety net in our application.
Another advantage of having DLQs are that we can set alarm based on the number of messages in the queue. This enables us to identify the specific part of the system encountering errors, including the exact producer or consumer component affected by the failure and quickly react to the failure.
There are many AWS services that support DLQ feature such as SQS, SNS, Lambda, EventBridge, StepFunctions, etc. They are very easy to set up, economical and can be very useful to improve the resilience of your system.
4. Retries #
Retrying is one of the fundamental actions we take if we cannot deliver a message to a consumer application in the first attempt. We make up to 100 attempts to deliver the message successfully to the customer within a 24-hour timeframe.
It is important that we don’t perform retries in regular intervals. We use Exponential Backoff And Jitter mechanism. This enables efficient retries without overloading our systems, while also safeguarding the consumer application.
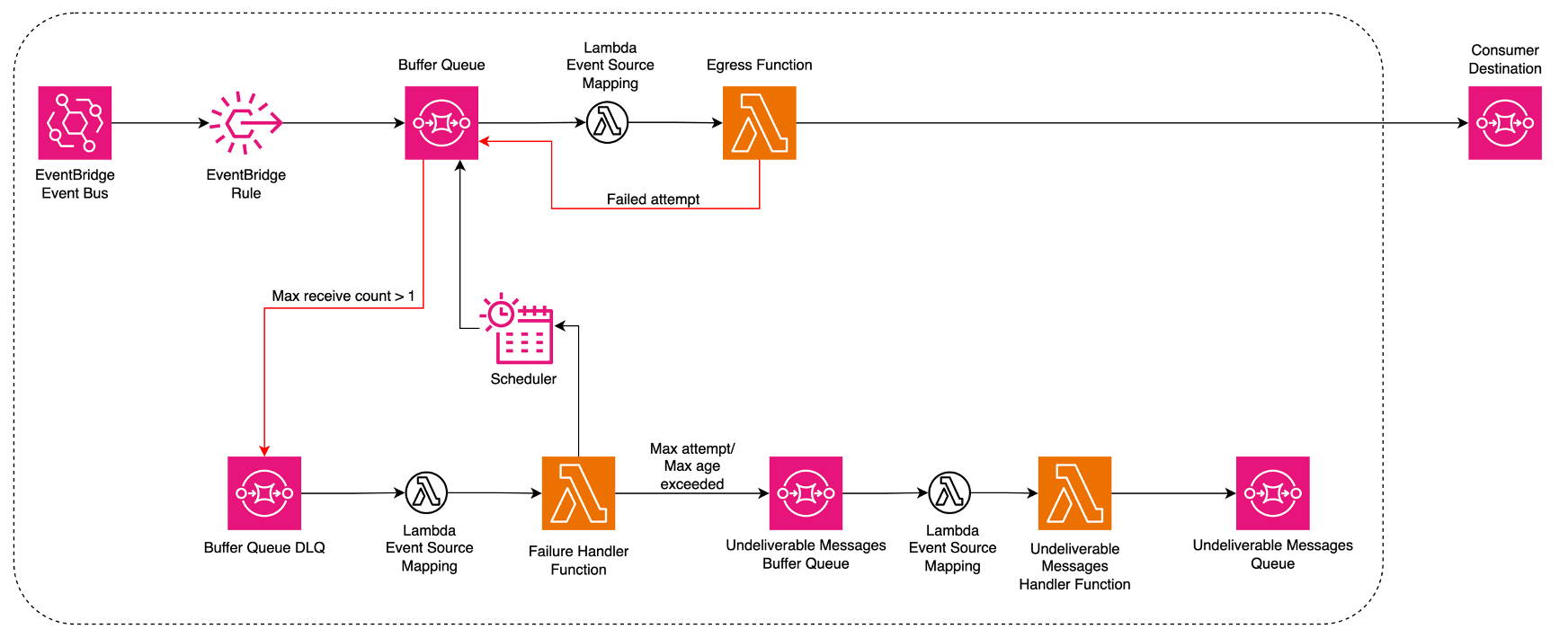
Buffer Queue is the event source to deliver the messages to the consumer applications. When the egress Lambda function failed to deliver the message to the consumer, it will be send back to the Buffer Queue, and we have max receive count to 1, which results in sending the message to the Buffer DLQ. The failure handler Lambda function consumes the messages in the Buffer DLQ, and calculates the next retry time based on the retry attempt. Here, we use either EventBridge Scheduler or SQS delayed messages feature to send the message back to the Buffer Queue for retrying in the specific time. This cycle continues until the message is delivered successfully or retried for 100 times within 24 hours.
Typically, this retry mechanism is sufficient for delivering the message to the consumer successfully.
5. Redrive #
In some cases, there are messages that were retried 100 times yet failed to deliver to the consumer application. Then the system concludes that the message cannot be delivered to the consumer. So, those messages will be sent to a final DLQ. And system will automatically send a message to the owners of the consumer application notifying that there are un-deliverable messages available.
At this point, the owners of the consumer application can have 2 options in our self service web portal. They can choose to drop those messages and the DLQ will be purged. This is feasible because the DLQ is exclusively for that individual consumer. Else, they can choose to re-drive those failed messages. In re-drive, those messages will be put back to the Buffer Queue for another round of processing.
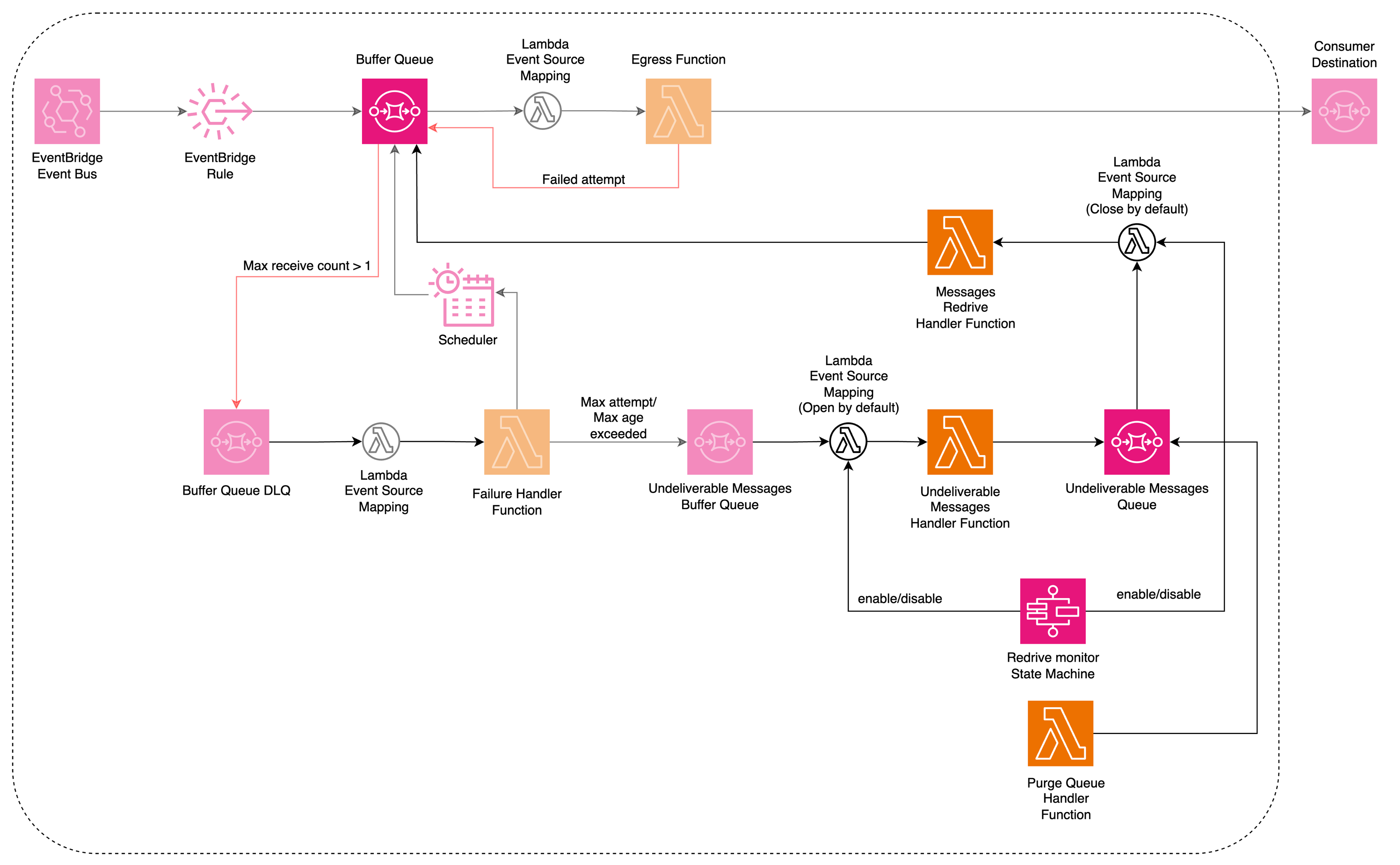
EBE is a “dumb pipe” which only delivers the messages to the consumers and it doesn’t have any knowledge over the contents and the processing of the messages. Because of this reason, system itself asks the respective owner of the consumer application to take action on the messages that were failed to deliver.
Conclusion #
Due to the critical nature of the application it is really important to make sure the EBE application maintains a high resilience, otherwise it will directly affect the business continuity.
By implementing a well designed solution using the tools and serverless technologies provided by AWS, we were able to increase the resilience of the system and make sure it recovers itself from any unexpected failures and the effect is minimised so that most part of the application runs without any interruption.
👋 I regularly create content on AWS and Serverless, and if you’re interested, feel free to follow / connect with me so you don’t miss out on my latest posts!
- LinkedIn: https://www.linkedin.com/in/pubudusj
- Twitter/X: https://x.com/pubudusj