Self healing Serverless App with Lambda Destinations and EventBridge

Table of Contents
AWS CTO, Werner Vogel once said - “Everything Fails All the Time”. No matter what technology you use, it is impossible to build a system that never fails. Serverless is no exception.
While it is important to reduce the possibility of failing a system, equally it is important to react fast to mitigate the issues when errors occur. Retrying is one of the basic steps towards fixing temporary issues. Further it will be great if the system can heal by itself without any additional input or action.
In this blog post, I discuss a scenario where a Lambda based Serverless application reacts to the errors occurring and attempts to re-drive messages to the origin in order to retry in a more controlled manner. For this, I use Lambda destinations, Event Bridge, Event Bridge Pipe and related technologies.
Dead Letter Queue Vs Lambda Destinations #
Dead letter queues are great as a way to preserve the messages that were failed to process. For example, assume a scenario where a Lambda function is triggered by a SNS topic. Whenever there is an error in the Lambda execution, we can directly send the original message into a pre configured Dead Letter Queue.
However, the downside is, only the original message will be added to the DLQ. No information is available as to WHY the message was unable to be processed.
In contrast, if we have a Lambda Destination configured to the same queue for the fail scenario, a message will be added to the DLQ with more useful information along with the original payload.
Below is the example message structure for the message added to queue via Lambda Destinations:
{
"version":"1.0",
"timestamp":"2023-03-12T11:20:25.428Z",
"requestContext":{
"requestId":"f05e5d90-2b5f-44f2-812a-8ccad64a5795",
"functionArn":"arn:aws:lambda:...",
"condition":"RetriesExhausted",
"approximateInvokeCount":1
},
"requestPayload":{
"Records":[
{
...
}
]
},
"responseContext":{
"statusCode":200,
"executedVersion":"$LATEST",
"functionError":"Unhandled"
},
"responsePayload":{
"errorMessage":"timeout exceeded",
"errorType":"RemoteDisconnected",
"requestId":"f05e5d90-2b5f-44f2-812a-8ccad64a5795",
"stackTrace":[
"File \"/var/task/index.py\\",
"line 6 in handler\\n raise http.client.RemoteDisconnected(\\'timeout exceeded\\')\\n"
]
}
}
These additional details are useful to determine the next steps of the process if (and how) we are going to retry these messages.
About this project #
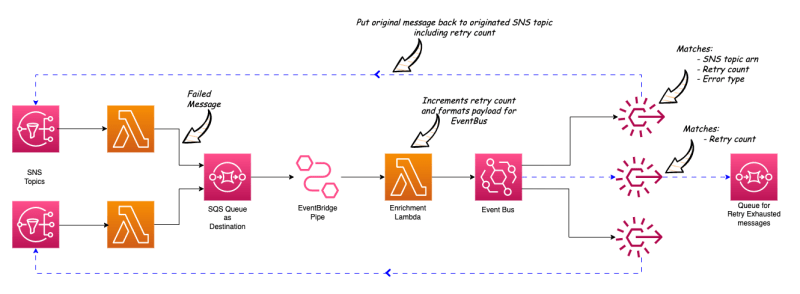
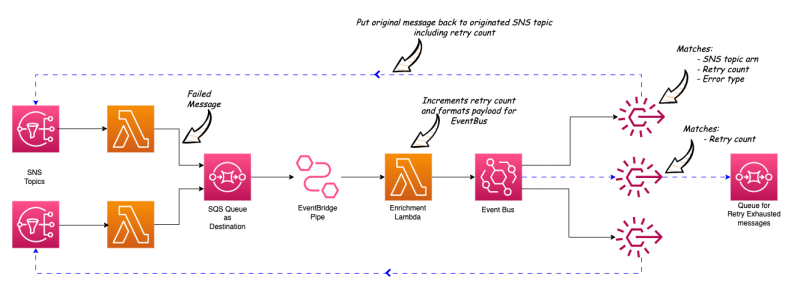
In this project, I have 2 SNS topics which are the triggers for 2 Lambda functions. One Lambda function throws an error as it returns from a http client when calling a remote API. The other Lambda function throws an type error which is an error in the Lambda code itself.
Both Lambda functions have Lambda Destination configured for the failed scenario into the same SQS queue (Dead Letter Queue).
EventBridge Pipe is configured to poll the messages from this Dead Letter Queue.
An Enrichment Lambda function is configured in the EB Pipe to extract the data from the DLQ message and format the message into the below structure. Also, within this Enrichment Lambda function, the retry count is added or incremented by 1.
{
"payload": original_message,
"meta": {
"source_topic": topic_arn,
"error_type": error_type_extracted_from_message,
"retry_count": incremented_retry_count,
"response_payload": response_payload_from_message,
}
}
EventBridge Pipe has Event Bus configured as the target. So these formatted messages are sent to the Event Bus.
In the Event Bus, there are 3 rules defined.
Rule #1 #
-
First condition matches the source SNS Topic ARN, the Error Type and the retry count.
-
Here, the Error Type condition matches messages that are NOT in a pre-defined error types list.
-
And it checks if the retry count is less than 3.
If these conditions are met, the message will be sent back to the source SNS topic using the rule target.
Rule #2 #
-
Second rule (same as first rule) matches the other source SNS Topic ARN, and the Error Type and the retry count.
-
Here, the Error Type condition matches messages that are NOT in the same predefined error types list.
-
And it checks if the retry count is less than 5.
If these conditions are met, the message will be sent back to the second SNS topic using the rule target.
Rule #3 #
- Third rule matches any messages that do not match with the above 2 rules.
There is a SQS queue (retry exhausted queue) defined for this rule as the target and any messages exceeding the retry count will be sent to this queue.
Try this yourself #
I have created a sample project for you to test this scenario in your AWS account. This is created using AWS CDK v2 with Python. So, you need CDK v2 and Python installed in your environment.
Below are the deployment details.
- Clone the repository: https://github.com/pubudusj/serverless-conditional-error-retry
- Go into the cloned directory.
- To manually create a virtualenv on MacOS and Linux:
$ python3 -m venv .venv - After the init process completes and the virtualenv is created, you can use the following step to activate your virtualenv.
$ source .venv/bin/activate - If you are a Windows platform, you would activate the virtualenv using:
% .venv\Scripts\activate.bat - Once the virtualenv is activated, you can install the required dependencies.
$ pip install -r requirements.txt - Then, deploy the application:
$ cdk deploy - Once the application is deployed, in the output you can see values for SNS topics
SourceTopicOne,SourceTopicTwoand SQS QueueRetryExhaustedQueuewhich are required for testing the application.
Testing #
-
Publish messages for both SNS topics with below payload structure:
{ "hello": "world", "source_sns": "one|two" } -
This will trigger two Lambda functions.
-
First Lambda Function will throw an http client error and the second Lambda function will trow a key error for this payload.
-
In few moments, if you check the messages in RetryExhaustedQueue , you can see the message that was processed with Lambda one has reached to the queue after 3 retries and the messages processed with Lambda two has reached to the queue without retry (because the error type is ‘KeyError’ which is defined in the list of errors that should not retry).
Reasoning #
The second Lambda function has an error in the code, so no matter how many times you retry, it fails (until you fix the code).
However in a scenario as in the first Lambda function where you received an error from an external API which is most likely a temporary issue, you will need to retry.
Also, we have defined the number of retries per each EB rule. This way we can control the retries for each of the components or sources and will not end up in an infinite loop if the error is not fixed.
Conclusion #
Retrying on error and re-driving the messages to the sources is one of the simple yet effective way to mitigate any temporary errors. However, if we don’t control the retry behaviour based on the error type, we will end up wasting resources.
With this proposed solution, we can control the retry behaviour based on no of attempts, error type and per source as well. Which will make a more controlled self-healing application.
Further, with the latest addition to AWS Serverless services, the Event Bridge Pipe, it is easy to connect sources and targets with low code and build integration fast between different AWS Serverless services.
Useful Links #
-
Lambda Destinations: https://aws.amazon.com/blogs/compute/introducing-aws-lambda-destinations/
-
EventBridge Pipes documentation: https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-pipes.html
-
Cloudformation API for Pipes: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-pipes-pipe.html
-
Pipes Documentation for CDK v2 Python: https://docs.aws.amazon.com/cdk/api/v2/python/aws_cdk.aws_pipes/CfnPipe.html
👋 I regularly create content on AWS and Serverless, and if you’re interested, feel free to follow / connect with me so you don’t miss out on my latest posts!
- LinkedIn: https://www.linkedin.com/in/pubudusj
- Twitter/X: https://x.com/pubudusj